Пеликаны, сарказм и логические игры — забавные LLM-бенчмарки
Новые нейронки появляются чуть ли не еженедельно и каждая борется за первенство в лидербордах. Но есть и другой способ оценить их — например, с помощью необычных тестов. Мы в beeline cloud [1] подобрали креативные бенчмарки: от рисования птиц на велосипедах до игр в духе логических загадок с наводящими вопросами.

Проверка птицей
Название бенчмарка Pelicans on Bicycles [2] говорит само за себя — в этом тесте нейронка должна сгенерировать код SVG-изображения с пеликаном на велосипеде. Насколько правдоподобно получается рисунок — настолько высоко оценивается нейросеть.
Этот своеобразный тест придумал (и активно использует) бывший технический директор онлайн-платформы для организации мероприятий Eventbrite Саймон Уиллисон [3]. Сейчас он занимается опенсорсом и исследованиями в сфере машинного обучения [4].
Саймон использовал свой метод, чтобы оценить возможности моделей, опубликованных с декабря 2024 года. Результатами он поделился на конференции AI Engineer World’s Fair в Сан-Франциско и с читателями своего блога. Многие модели не сумели достойно изобразить не только самого пеликана, но и двухколесный транспорт.
Из трёх моделей ASW Nova от Amazon лишь nova-pro выдала едва похожий [5] на велосипед результат [у других же были бессмысленные абстракции].
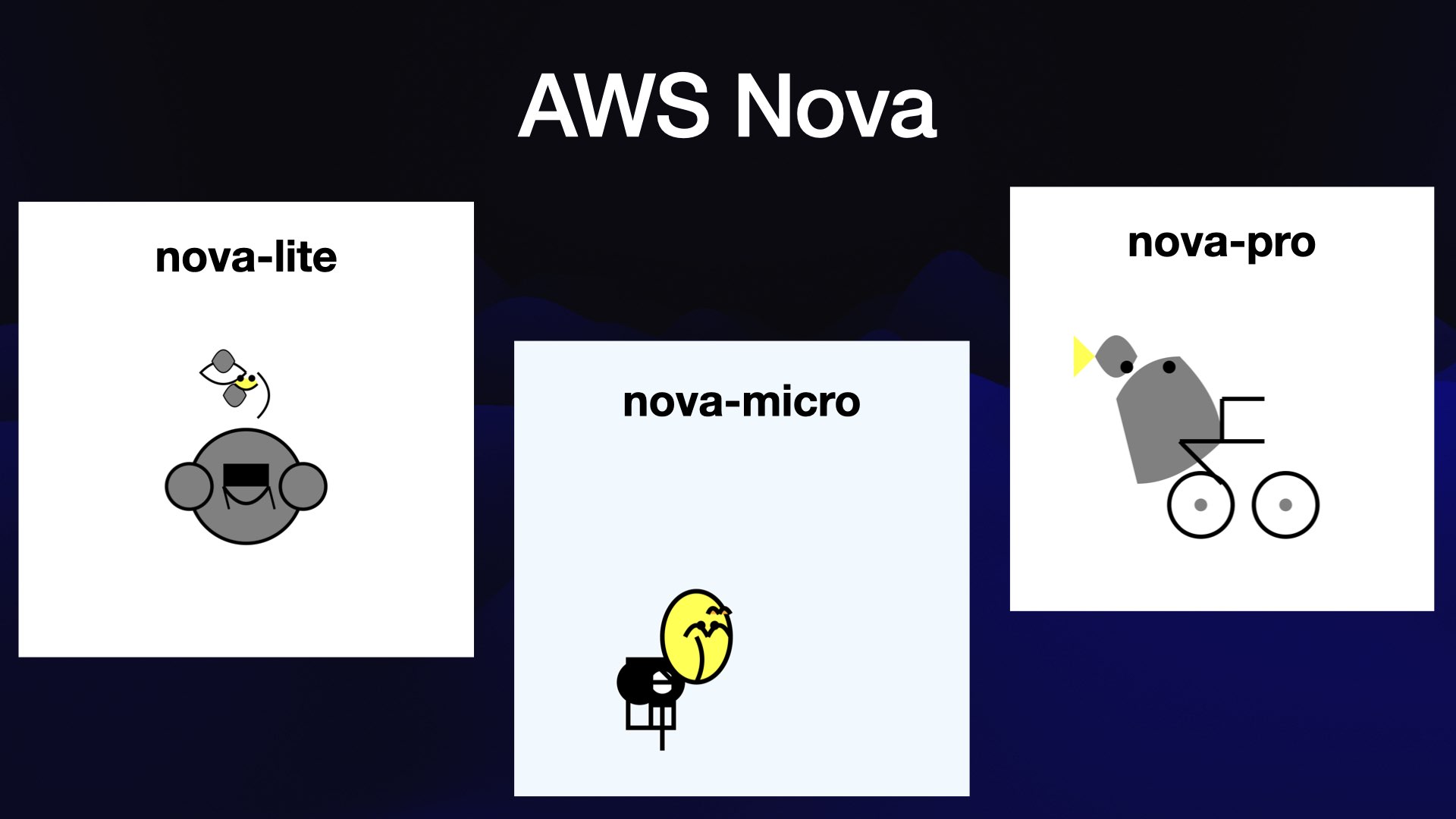{kind=link}
Также инженер проверил возможности DeepSeek-R1 — на изображении [6] можно угадать птицу и даже транспорт. Еще более качественные (хотя и далеко не идеальные) работы сгенерировали Gemini 2.5 Pro [7], o1-pro [8] и GPT 4.5 [9]. В целом на сайте Уиллисона есть 36 примеров [10] от различных моделей. Кстати, пеликан на велосипеде служит «лакмусовой бумажкой» и для систем ИИ, генерирующих видео. К примеру, Sora [11] смогла выдать [11] видеофрагмент с неплохим пеликаном на странном велосипеде.
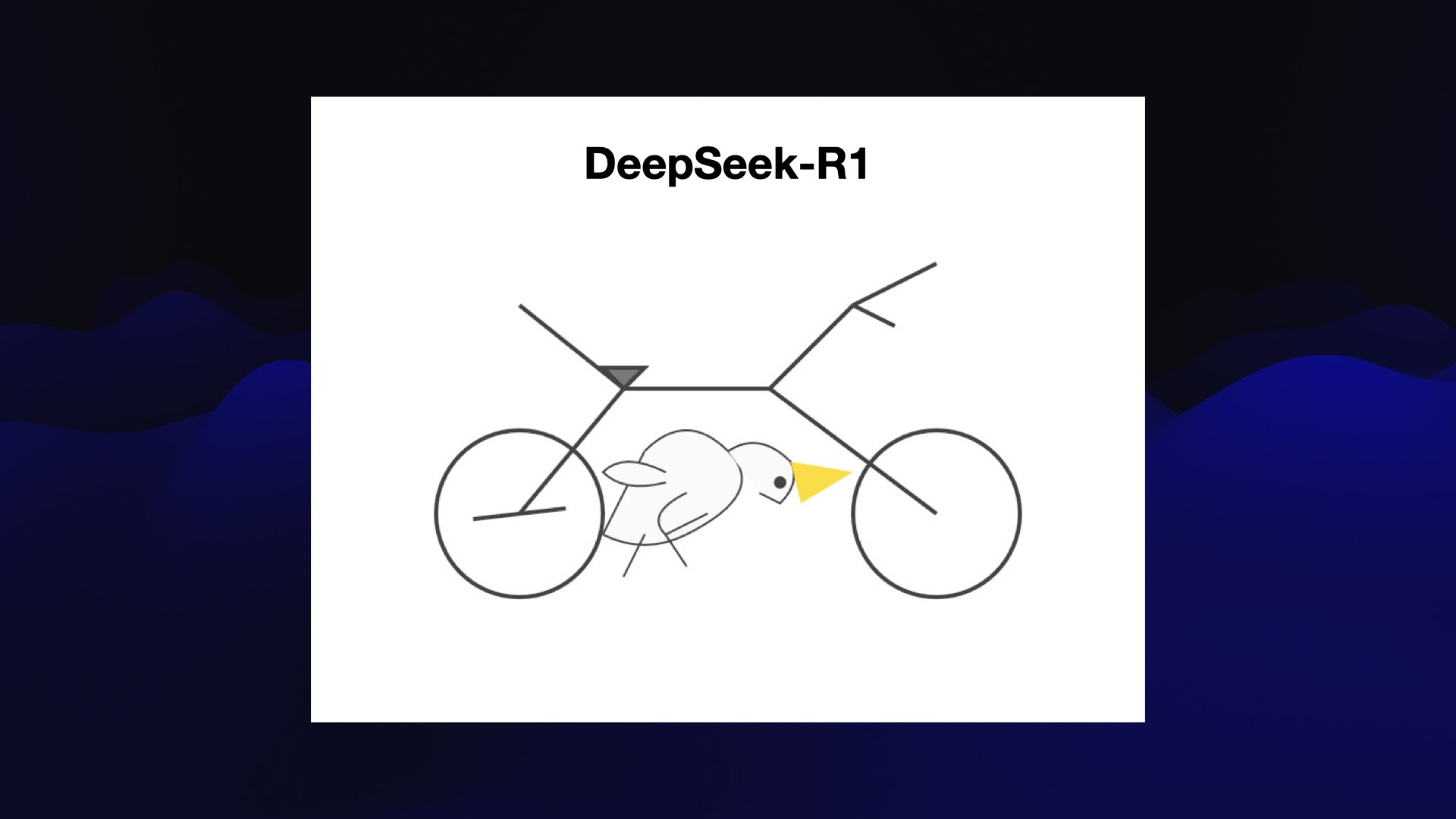{kind=link}
{kind=link}
{kind=link}
{kind=link}
Саймон признаётся, что поначалу идея подобного теста воспринималась им как шутка, однако теперь он считает [2] «проверку пеликанами» довольно эффективной: «Пеликаны великолепные птицы и их сложно нарисовать, а достоверно изобразить верхом на велосипеде — ещё сложнее». А вот к классическим лидербордам и бенчмаркам разработчик, напротив, потерял доверие [12] из-за недостатка прозрачности в оценках.
И бенчмарк привлек внимание [13] резидентов Hacker News. Там отметили [14], что такой подход можно применять при оценке работы LLM в области 3D-моделирования (например, для написания Python-кода в Blender). Хотя у нескольких комментаторов были претензии [15] к объективности тестирования по одному образцу, а не по усреднённому результату из десяти или более генераций. Еще один пользователь отметил [16], что вскоре системы ИИ начнут обучаться на работах Уиллисона и будут рисовать пеликанов все лучше и лучше.
Необычные задачи
Бывший астрофизик Хавард Твейт Иле [17] раньше занимался анализом данных в крупных космологических проектах COMAP [18] (изучение молекулярного газа и эволюции галактик) и Cosmoglobe [19] (космическая карта излучений обозреваемой вселенной). Сейчас он занимается исследованиями в ML и в этом году представил бенчмарк WeirdML [20]. Его цель — оценить способность LLM решать нестандартные задачи с минимумом подсказок.
Примером такой «странной» задачи может быть тест [21], в котором модели необходимо изучить облако из 512 точек в двухмерном пространстве и определить одну из пяти геометрических фигур (круг, квадрат, звезда и так далее). В легком варианте [22] задачи предложенная форма всегда расположена по центру, а в более сложном [23] — может быть повернута, смещена, а также увеличена или уменьшена.
Еще есть задача по поиску и «склейке» перемешанных фрагментов изображений [24] (например, это могут быть картинки [25] с туфлей или платьем). Нейронке предоставляется массив данных из двух тысяч образцов в оттенках серого [26], каждый из которых был разбит на девять фрагментов размером 9×9 пикселей. Модель должна составить пазл 27×27 и не перепутать элементы.
{kind=link}
Наконец, третий тест, в котором модель должна попытаться предсказать исход [27] шахматной партии на основе классической текстовой нотации. В качестве датасета для обучения взяты игры начинающих. Также с вероятностью 50% последний ход белых или чёрных в каждой партии может быть удалён из записи, чтобы LLM было ещё труднее просчитывать результаты.

Некоторым показалось [28], что этот бенчмарк, как и многие другие аналоги, является испытанием ради испытания, и его может ждать судьба остальных тестов. Он может стать популярным, сформируются лидерборды, а затем команды разработчиков начнут настраивать свои LLM для демонстрации высоких результатов именно в этом бенчмарке. Однако Иле считает [28], что подобные методы проверки всё же несут пользу — позволяют в какой-то мере объективно оценить и сравнить возможности ведущих нейронок.
Игра в данетки
Тест LatEval [29] оценивает LLM в латеральном мышлении [30]. В этом бенчмарке модели сравнивают по способности формулировать и задавать вопросы для решения головоломок. Также проверяется возможность системы ИИ использовать имеющуюся информацию и определять истину с помощью логических рассуждений. LatEval представили в своей научной работе 2023 году китайские исследователи из Международной высшей школы Цинхуа в Шэньчжэне и Университета Цинхуа.
За основу для задач в бенчмарке взяты популярные наборы пазлов с различных веб-сайтов — всего 325 штук на китайском и английском языках. В частности, в одной из задач LLM предлагается сыграть в классические данетки [31]. Тестируемая модель выступает в роли игрока, решающего головоломку, а GPT-4 или GPT-3.5 — в роли ведущего. Например, LLM задают вопрос: «Лодка с пассажирами плывет по реке, но внезапно переворачивается и большинство людей тонет. Почему?». С помощью серии закрытых вопросов модель должна прийти к корректному ответу: «На лодку упала крупная змея, пассажиры в ужасе бросились на противоположный борт, отчего судно перевернулось».
Ведущий оценивает, насколько задаваемые игроком-нейросетью вопросы соответствуют разгадке, разнообразие уточнений, их последовательность и логичность, а также среднее число «ходов» для нахождения решения. Для проверки результатов использовали метод краудсорсинговой оценки — трое студентов проанализировали около пятидесяти сессий. Как оказалось, ни одна из моделей не продемонстрировала уверенных результатов.
Тест британским юмором
Система бенчмарков EQ-Bench [32] позволяет оценить «эмоциональный интеллект» LLM — эмпатию, проницательность, социальные навыки. В 2023 году ее представил инженер Сэмюэл Пэч, сопроводив объемной научной работой [33]. Одним из наиболее необычных компонентов EQ-Bench является бенчмарк BuzzBench [34]. Его цель — определить, может ли ML-модель понимать шутки из культового британского шоу Never Mind the Buzzcocks [35]. Задача LLM — объяснить комический эффект и предсказать, понравится ли шутка аудитории. Ответы оценивает другая интеллектуальная система, которая ориентируется на объяснения, предоставляемые человеком.
В комментариях под постом [36] на Reddit по теме люди задались вопросом о субъективности юмора [37] и возможной предвзятости модели-оценщика. Однако автор считает [38] свой бенчмарк скорее шуткой, нежели полноценным и серьёзным исследованием. В то же время в системе EQ-Bench можно найти и другие тесты. Скажем, модуль Judgemark проверяет, насколько эффективно LLM способна оценивать небольшие художественные произведения, опираясь на набор из 36 положительных/отрицательных критериев. А бенчмарк Creative Writing позволяет оценить возможности моделей в генерации эмоциональных и творческих текстов на основе 32 заданий.
Больше тонкостей юмора
В 2024 году специалисты из ИТ-консалтинговой фирмы F’inn захотели выяснить [39], насколько эффективно системы ИИ генерируют юмор и способны ли они улавливать тонкости, связанные с эмоциональным контекстом. Чтобы ответить на этот вопрос, они попросили GPT-4/3.5, Gemini и пару других моделей написать самую смешную шутку, на которую они только способны. По большей части модели генерировали бессмысленный текст, хотя некоторые из них предупредили, что юмор субъективен.

Вообще, тема юмора достаточно часто затрагивается разработчиками ML-моделей. Так, один энтузиаст разработал [40] виджет-трекер для отображения прогресса выполнения еженедельных задач. Позже он добавил в него интерактивную метрику в виде шкалы счастья со смайликами. Программист попросил несколько нейронок сгенерировать шкалу эмодзи, в которой эмоции [41] были бы распределены по возрастанию — от сдержанной улыбки до восторга. С задачей более-менее справились только Claude 3.5 Sonnet и Perplexity. А у остальных — не получилось: какие-то нейросети использовали одну и ту же эмодзи, а другие без какой-либо логики расставили случайные «позитивные» смайлики.
В 2024 году анонимные специалисты пошли дальше в изучении возможностей систем ИИ в вопросах юмора. Они опубликовали исследование [42], посвящённое пониманию LLM сарказма и иронии. Для него они разработали бенчмарк MOCK, оценивающий способность моделей улавливать саркастический контекст, выбирать наиболее подходящий вариант шутки и объяснять суть.
Обучающий датасет MOCK состоит из более чем 11 тыс. юмористических рисунков, 28 тыс. постов из соцсетей и тысяч диалогов из комедийных шоу. Чтобы нейросеть могла анализировать визуальную информацию, изображения сопроводили текстовыми описаниями с аннотациями.
В исследовании инженеры тестировали модели как в базовом режиме, так и с тонкой настройкой. Например, на одном изображении доктор пытался услышать сердцебиение Супермена (хотя это невозможно). Базовые модели с трудом определяли, в чём заключается комичность ситуации. Однако нейросети с тонкой настройкой в целом поняли смысл комикса.
Системы ИИ против веселья
В этой работе [43] 2024 года специалисты Колумбийского университета задались вопросом, возможно ли может ли нейросеть генерировать синтетические данные для детектирования юмора. В исследовании специалисты использовали датасет Unfun. Он был сформирован в 2019 году в ходе лингвистической игры, в которой участники переделывали изначально сатирические заголовки статей в серьёзные с минимальным количеством правок. В набор поместили около 11 тыс. отредактированных заголовков — и на их основе специалисты оценили способности LLM по включению/исключению юмора.
Оказалось, если системы ИИ с чем-то справляются в вопросах юмора, то с переводом интересных и ярких описаний в нейтральный стиль; как выражаются авторы, «лишать их шуточности» (unfun). Например, GPT-4 переделала заголовок «Том Петти сыграет что-то новенькое…» в безэмоциональный «Том Петти исполнит новый материал…».
beeline cloud [1] — secure cloud provider. Разрабатываем облачные решения, чтобы вы предоставляли клиентам лучшие сервисы.
Автор: beeline_cloud
Источник [44]
Сайт-источник BrainTools: https://www.braintools.ru
Путь до страницы источника: https://www.braintools.ru/article/17242
URLs in this post:
[1] beeline cloud: https://cloud.beeline.ru/?utm_source=habr&utm_medium=post&utm_campaign=main&utm_content=llm_benchmark&utm_term=07_25
[2] Pelicans on Bicycles: https://simonwillison.net/2025/Jun/6/six-months-in-llms/
[3] Саймон Уиллисон: https://simonwillison.net/about/
[4] обучения: http://www.braintools.ru/article/5125
[5] едва похожий: https://static.simonwillison.net/static/2025/ai-worlds-fair/ai-worlds-fair-2025-05.jpeg
[6] изображении: https://static.simonwillison.net/static/2025/ai-worlds-fair/ai-worlds-fair-2025-10.jpeg
[7] Gemini 2.5 Pro: https://static.simonwillison.net/static/2025/ai-worlds-fair/ai-worlds-fair-2025-19.jpeg
[8] o1-pro: https://static.simonwillison.net/static/2025/ai-worlds-fair/ai-worlds-fair-2025-18.jpeg
[9] GPT 4.5: https://static.simonwillison.net/static/2025/ai-worlds-fair/ai-worlds-fair-2025-15.jpeg
[10] 36 примеров: https://simonwillison.net/tags/pelican-riding-a-bicycle/
[11] Sora: https://simonwillison.net/2024/Dec/9/
[12] потерял доверие: https://simonwillison.net/2025/Apr/30/criticism-of-the-chatbot-arena/
[13] внимание: http://www.braintools.ru/article/7595
[14] отметили: https://news.ycombinator.com/item?id=44217108
[15] претензии: https://news.ycombinator.com/item?id=44216129
[16] отметил: https://news.ycombinator.com/item?id=44216265
[17] Хавард Твейт Иле: https://htihle.github.io/
[18] COMAP: https://science.jpl.nasa.gov/projects/comap/
[19] Cosmoglobe: https://www.mn.uio.no/astro/english/research/research-projects/cosmoglobe/
[20] WeirdML: https://www.lesswrong.com/posts/LfQCzph7rc2vxpweS/introducing-the-weirdml-benchmark
[21] тест: https://htihle.github.io/prompts/task_prompt_shapes_easy.html
[22] легком варианте: https://res.cloudinary.com/lesswrong-2-0/image/upload/f_auto,q_auto/v1/mirroredImages/LfQCzph7rc2vxpweS/dzkbi4k6lcnwo4vnrwdn
[23] более сложном: https://res.cloudinary.com/lesswrong-2-0/image/upload/f_auto,q_auto/v1/mirroredImages/LfQCzph7rc2vxpweS/oxqtbe4kcokonqkfxi3m
[24] изображений: https://htihle.github.io/prompts/task_prompt_shuffle_easy.html
[25] картинки: https://htihle.github.io/images/scrambled_vs_unscrambled_easy.png
[26] оттенках серого: https://en.wikipedia.org/wiki/Grayscale
[27] попытаться предсказать исход: https://htihle.github.io/prompts/task_prompt_chess_winners.html
[28] показалось: https://www.lesswrong.com/posts/LfQCzph7rc2vxpweS/introducing-the-weirdml-benchmark?commentId=q86ogStKyge9Jznpv
[29] LatEval: https://aclanthology.org/2024.lrec-main.889.pdf
[30] латеральном мышлении: https://en.wikipedia.org/wiki/Lateral_thinking
[31] данетки: https://en.wikipedia.org/wiki/Situation_puzzle
[32] EQ-Bench: https://eqbench.com/about.html
[33] научной работой: https://arxiv.org/pdf/2312.06281
[34] BuzzBench: https://eqbench.com/buzzbench.html
[35] Never Mind the Buzzcocks: https://en.wikipedia.org/wiki/Never_Mind_the_Buzzcocks
[36] постом: https://www.reddit.com/r/LocalLLaMA/comments/1hufsgu/i_made_a_difficult_humour_analysis_benchmark/
[37] юмора: http://www.braintools.ru/article/3517
[38] считает: https://www.reddit.com/r/LocalLLaMA/comments/1hufsgu/comment/m5l6fxu/
[39] захотели выяснить: https://www.finn-group.com/post/the-last-laugh-exploring-the-role-of-humor-as-a-benchmark-for-large-language-models
[40] разработал: https://smileaibenchmark.com/
[41] эмоции: http://www.braintools.ru/article/9540
[42] исследование: https://openreview.net/pdf?id=ld5fGYUK9n
[43] работе: https://arxiv.org/pdf/2403.00794
[44] Источник: https://habr.com/ru/companies/beeline_cloud/articles/927284/?utm_campaign=927284&utm_source=habrahabr&utm_medium=rss
Нажмите здесь для печати.