

“Этот алгоритм работает за O(n log n)”, часто вспоминается эта фраза, когда мы хотим пойти на собеседование, звучит как что-то абстрактное из учебников по алгоритмам. На самом деле Big O — это практичный инструмент описания производительности функции без привязки к конкретному железу или времени выполнения.
Почему бы не пойти простым путем и не измерять время выполнения каждого алгоритма?
Время сильно зависит от разных параметров, рассмотрим некоторые из них:
-
От железа: на одном ноутбуке — 37 мс, на сервере — 12 мс…
-
От входных данных: 1000 элементов — быстро, 1 000 000 — неприятно, 1 000 000 000 — можно сходить за кофе (или в отпуск)
И самое важное то, что единичное измерение не показывает поведение при росте нагрузки. А именно это нас и интересует. Big O показывает как изменяется время исполнения при увеличении размера входных данных. Буква O в Big O расшифровывается как order of growth (порядок роста).
Линейное время: O(N)
Представим, что у нас есть список ID пользователей, и нам нужно проверить, есть ли конкретный ID в этом списке. Будем рассматривать худший случай, когда нужного элемента нет или он стоит в самом конце, и нам придется сделать максимальное количество сравнений
def contains(items: Sequence[UserID], target: UserID) -> bool: for item in items: if item == target: return True return False

Если вызвать contains на 100 элементах, то максимум мы получим 100 сравнений, на 200 элементах цикл выполнится 200 раз и займет примерно в 2 раза больше времени. Это происходит из-за того, что цикл выполнится n раз. При увеличении n добавляется и количество итераций.
Проверим это на примере
import time import statistics from typing import NewType, Sequence UserID = NewType("UserID", int) def contains(items: Sequence[UserID], target: UserID) -> bool: for item in items: if item == target: return True return False def bench(size, repeats=15): items: list[UserID] = [UserID(i) for i in range(size)] target: UserID = UserID(-1) # худший случай: проход до конца times = [] for _ in range(repeats): start = time.perf_counter() contains(items, target) times.append(time.perf_counter() - start) return statistics.median(times) sizes = [100_000, 1_000_000, 10_000_000, 100_000_000] prev = None for size in sizes: t = bench(size) if prev is None: print(f"{size:>12} → {t:.6f} sec") else: print(f"{size:>12} → {t:.6f} sec (×{t/prev:.2f})") prev = t # 100000 → 0.000595 sec # 1000000 → 0.005797 sec (×9.75) # 10000000 → 0.055516 sec (×9.58) # 100000000 → 0.541713 sec (×9.76)

Как видно из примера выше при увеличении размера входных данных в 10 раз время растет также примерно в 10 раз. Отклонения дают кэш, работа ОС и другие накладные расходы интерпретатора, но тренд остается линейным. Именно это мы называем O(n)
Константное время: O(1)
Допустим, что в этот раз нам будет приходить set пользователей
def contains(items: set[UserID], target: UserID) -> bool: return target in items

Проверка вхождения элемента в хэш-таблицу занимает O(1), посмотрим на бенчмарки
import time import statistics from typing import NewType UserID = NewType("UserID", int) def contains(items: set[UserID], target: UserID) -> bool: return target in items def benchmark(size: int, repeats: int = 100_000) -> float: items: set[UserID] = {UserID(i) for i in range(size)} target: UserID = UserID(-1) times: list[float] = [] for _ in range(7): start = time.perf_counter() for __ in range(repeats): contains(items, target) elapsed = time.perf_counter() - start times.append(elapsed / repeats) return statistics.median(times) sizes = [100_000, 1_000_000, 10_000_000, 100_000_000] prev: float | None = None for size in sizes: t = benchmark(size) if prev is None: print(f"{size:>10} → {t:.9f} sec per check") else: print(f"{size:>10} → {t:.9f} sec per check (×{t/prev:.2f})") prev = t # 100000 → 0.000000025 sec per check # 1000000 → 0.000000026 sec per check (×1.04) # 10000000 → 0.000000026 sec per check (×0.98) # 100000000 → 0.000000025 sec per check (×0.98)

Видно, что даже на огромных входных данных время на одну операцию остается примерно одинаковым, независимо от размера множества.

Логарифмическое время: O(log n)
Бинарный поиск работает с отсортированным списком, на каждом шаге уменьшая область поиска вдвое
Это означает, что даже если список вдвое больше, число шагов увеличивается лишь на 1, поэтому такой алгоритм имеет сложность O(log n).
В худшем случае количество шагов растет очень медленно:
-
для массива длиной 10 потребуется максимум 4 шага
-
для 100 — максимум 7 шагов
-
для 1 000 — максимум 10 шагов
-
для 1 000 000 — максимум 20 шагов
Напишем код и проверим:
import time import statistics from typing import NewType, Sequence UserID = NewType("UserID", int) def binary_search(items: Sequence[UserID], target: UserID) -> bool: lo, hi = 0, len(items) - 1 while lo <= hi: mid = (lo + hi) // 2 v = items[mid] if v == target: return True if v < target: lo = mid + 1 else: hi = mid - 1 return False def benchmark(size: int, repeats: int = 100_000) -> float: items: list[UserID] = [UserID(i) for i in range(size)] target: UserID = UserID(-1) times: list[float] = [] for _ in range(7): start = time.perf_counter() for __ in range(repeats): binary_search(items, target) elapsed = time.perf_counter() - start times.append(elapsed / repeats) return statistics.median(times) sizes = [100_000, 1_000_000, 10_000_000, 100_000_000] prev: float | None = None for size in sizes: t = benchmark(size) if prev is None: print(f"{size:>10} → {t:.9f} sec per search") else: print(f"{size:>10} → {t:.9f} sec per search (×{t/prev:.2f})") prev = t # 100000 → 0.000000769 sec per search # 1000000 → 0.000000891 sec per search (×1.16) # 10000000 �� 0.000001049 sec per search (×1.18) # 100000000 → 0.000001185 sec per search (×1.13)

Квадратичное время: O(N^2)
Это область “вложенных циклов”. Один из примеров, который сразу приходит в голову — когда для каждого элемента списка нужно просканировать весь этот же список еще раз. Например, если мы хотим найти дубликаты в массиве самым простым (и самым медленным) способом.
import time import statistics def has_duplicates(items: list[int]) -> bool: for i in range(len(items)): for j in range(i + 1, len(items)): if items[i] == items[j]: return True return False def bench(size, repeats=15): items: list[int] = [i for i in range(size)] times = [] for _ in range(repeats): start = time.perf_counter() has_duplicates(items) times.append(time.perf_counter() - start) return statistics.median(times) sizes = [1_000, 2_000, 4_000, 8_000, 16_000] prev = None for size in sizes: t = bench(size) if prev is None: print(f"{size:>12} → {t:.6f} sec") else: print(f"{size:>12} → {t:.6f} sec (×{t/prev:.2f})") prev = t # 1000 → 0.007976 sec # 2000 → 0.030892 sec (×3.87) # 4000 → 0.123686 sec (×4.00) # 8000 → 0.495934 sec (×4.01) # 16000 → 1.975878 sec (×3.98)

Здесь магия чисел работает против нас. Если входные данные увеличиваются в 10 раз, время выполнения увеличивается в 100 раз (10^2). Если в 100 раз — время в растет в 10 000 раз.
Обратите внимание: я уменьшил размер входных данных sizes в тысячи раз по сравнению с примером для O(n). Если для линейного алгоритма 100_000_000 элементов — это полсекунды, то для O(n^2) такое количество данных заставит компьютер работать очень и очень долго.
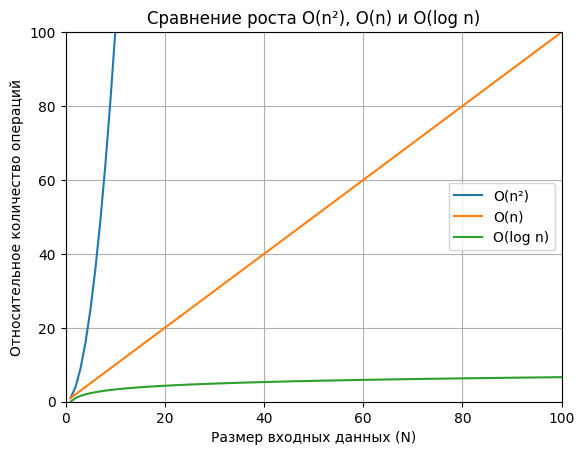
Почему это важно знать?
Часто O(n^2) появляется там, где вы его не ждете. Например, использование метода list.remove() или оператора in внутри цикла по этому же списку превращает ваш “линейный” код в квадратичный:
result = "" for char in long_list: result += char # Каждый раз выделяется новая память, копируя все предыдущие символы

Частые вопросы и подводные камни
Пока мы рассмотрели простые алгоритмы с одной коллекцией, на практике код бывает сложнее, и классические примеры начинают вызывать вопросы.
Откуда берутся O(N+M) и O(N*M)?
Часто мы работаем не с одним списком, а с двумя. Представьте функцию, которая принимает два массива разной длины и что-то с ними делает.
def get_two_maxes(arr1: list[int], arr2: list[int]) -> tuple[int, int]: max1 = max(arr1) max2 = max(arr2) return max1, max2

Здесь мы делаем два независимых прохода. Мы не можем сказать, что сложность O(N), тк массивы разные. Мы не можем сказать O(2N), тк N и M могут отличаться на порядки. Поэтому правильно сказать, что сложность O(N + M), где N – len(arr1), M – len(arr2).
А что, если нам нужно найти общие элементы (пересечение) в двух не отсортированных списках “в лоб”?
def find_duplicates(arr1: list[int], arr2: list[int]) -> list[int]: duplicates = [] for item1 in arr1: # Выполнится N раз for item2 in arr2: # Выполнится M раз для каждого N if item1 == item2: duplicates.append(item1) return duplicates

Мы не можем назвать это O(N^2), потому что списки независимы. Если arr1 имеет длину 10, а arr2 длину 1 000 000, O(N^2) даст абсолютно ложное представление о скорости работы. Правильная асимптотика здесь — O(N*M).
Что такое N в сложных структурах?
На собеседованиях любят давать задачи, где структура чуть сложнее обычного массива. Представьте, что у нас есть словарь, где ключи — это ID групп (строки), а значения — списки пользователей в этих группах. Причем в одной группе может быть 2 человека, а в другой — 10 000.
groups = { "admin": ["alice", "bob"], "users": ["charlie", "dave", "eric", ...], "guests": ["frank"] }

Какая сложность будет у функции, которая печатает всех пользователей из всех групп?
def print_all_users(groups: dict[str, list[str]]): for group_id, users in groups.items(): # Проходим по всем ключам for user in users: # Проходим по списку внутри ключа print(user)

Тут легко ошибиться и сказать O(N^2), увидев вложенный цикл. Но так ли это?
В таких случаях важно сразу уточнить, что именно вы называете переменной N.
-
Если N — это количество групп (ключей), то мы не можем определить сложность, тк не знаем размеры списков
-
Если N — это общее количество пользователей во всех списках, то сложность будет O(N) (если считать, что у нас не может быть пустых групп)
Представьте, что у нас есть 1 000 000 групп, и в каждой по 1 человеку. Мы сделаем 1 000 000 итераций внешнего цикла. А теперь представьте, что у нас всего 1 группа, но в ней 1 000 000 человек. Внешний цикл сработает 1 раз, зато внутренний — миллион. В обоих случаях мы обработаем 1 000 000 элементов.
Когда вас спрашивают про Big O, и данные сложнее плоского списка — всегда уточняйте, что именно вы принимаете за N. Это покажет интервьюеру, что вы понимаете физический смысл производительности, а не просто зазубрили формулы.
Автор: qvntz
